本文介绍了缓存的基本概念与常见的缓存淘汰算法,以及一些进阶的缓存淘汰算法.如LIRS、ARC、W-Tiny-LFU等。
前置知识:基本的数据结构与算法
前言
前段时间由于插队了一个高优的项目导致倒排期,一直在加班赶工期,没有时间做技术产出,现在项目临近上线,总算有了一些时间,来把博客写一写。年前在看CSAPP,算是把上课没好好听的计组再认真的补了一遍,学习的过程中有所感悟,加上学习公司的缓存组件时又学了几个淘汰算法,遂把常见的缓存淘汰的算法做一个总结。缓存的另一些问题,如一致性、穿透、击穿、雪崩等暂不做描述,后续可能会单独开一章。
缓存简介
缓存是计算机科学领域中最常见的性能优化方式之一,在整个计算机领域中无处不在。要讲缓存就不得不先了解计算机存储器结构体系与局部性原理,他们是缓存存在的前提条件。而要理解计算机存储结构体系就要先理解程序的局部性原理。局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。局部性原理又分为 时间局部性 和 空间局部性,时间局部性指的是已经访问过的存储位置很有可能再次被访问,空间局部性指的是已经访问过的存储位置附近的存储位置很有可能也会被再次访问。
上述的解释比较抽象,具体举例来说,程序中通常存在大量的循环,循环中会多次执行相同的代码,访问同一些变量,这体现了程序的时间局部性;我们时常会做一些遍历数组的操作,数组的元素在内存中又是连续的,这体现了程序的空间局部性。又比如说在函数或方法中定义的局部变量通常都会多次访问,并且它们在栈中连续存储,这同时体现了程序的时间局部性和空间局部性。这样的例子有许多,局部性原理的体现在程序中几乎无处不在。
说完了局部性原理我们就可以来了解计算机存储器结构体系。任何东西都是有成本的,对于一个存储器来说,存取的速度就越快,就意味着相应的制作工艺就越精良,对应的制作成本就越高。你可以打开购物软件看看同样大小的内存条和硬盘对比一下价格直观的感受一下。这种制作成本决定了计算机不可能全部使用非常优秀的存储器来进行存储,否则太贵了。但我们也不能全使用非常大但是性能很差的存储器来进行存储,因为太慢了。
在局部性原理的前提下,我们可以认为大部分的存储不会经常被访问,我们经常访问的内存其实很少,于是我们可以将所有的数据存在一个虽然读取速度慢一点但是大一些的存储器里,然后将常用的数据存储在一个读取速度快但是小一些的存储器里,在需要用某个数据而小存储器里没有的时候再去大的存储器中取,根据局部性原理,我们可以从大的存储器中一次取多个连续的数据,然后存到小的存储器中,已经存满了如果小的存储器,就从小的存储器中选一些数据删掉换成新取出的数据。如果我们经常在小存储器中取到数据,即使偶尔需要到大存储器中取数据再存到小存储器中,依然是很赚的。这样我们就可以在较低的成本下获取较高的性能。出于制作成本的考虑,最终我们实际应用的是一个金字塔型的存储器结构体系,在《CSAPP》中有如下图
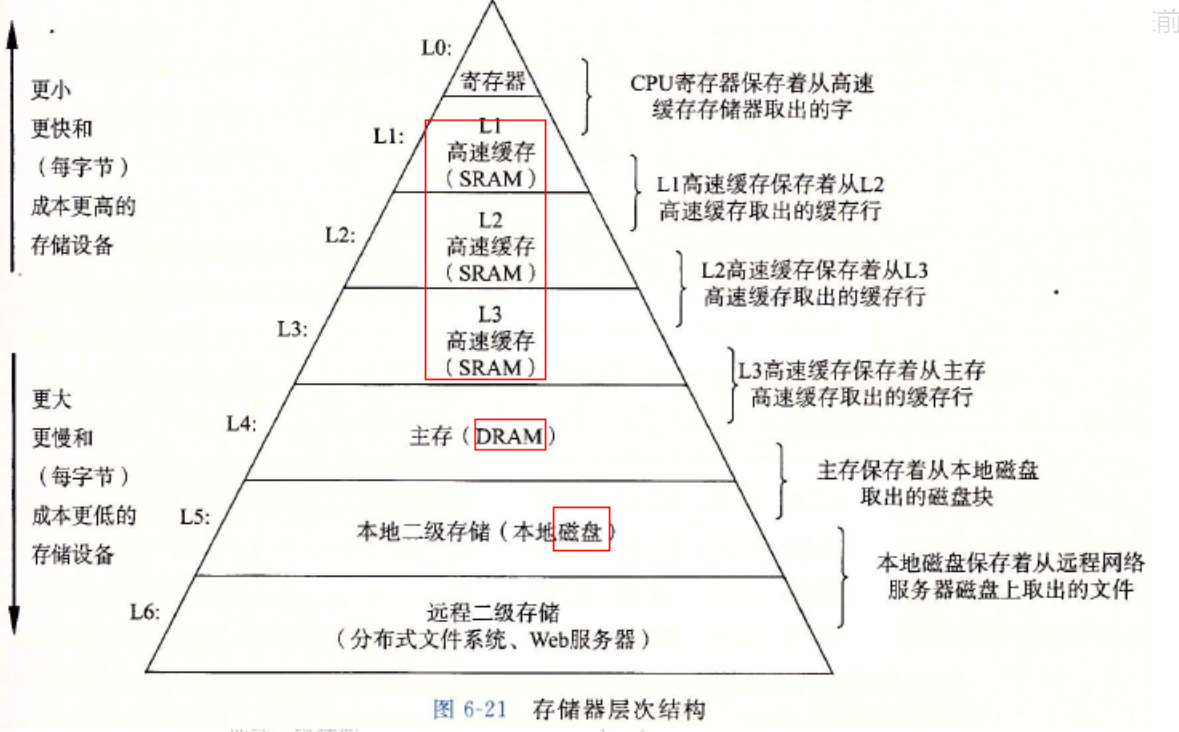
在上文中已经提到,我们使用分级的存储器来进行存储,上层存储器没有的时候我们到下层存储器中取,然后存入上层存储器中,上层存储器存满时选择部分数据抛弃然后将新数据存入上层存储器中。这其实就是缓存的基本思想。在整个存储器体系中,每一个上层的存储器本质上就是下层存储器的缓存。而选择将哪些数据抛弃的算法就是缓存淘汰算法。
我们使用缓存的目的是在较低的成本下获取较高的性能,因此缓存最关注的指标是缓存命中率,即在缓存中查到数据的次数/查数据的次数,当然,除此之外缓存的可用空间也要尽量大。在给定的大小下,提高缓存命中率最重要的就是缓存淘汰算法。在计算机科学中有一条定律叫做 “No silver bullets”——没有银弹,在不同的场景下最优秀的缓存算法是不同的,这也就促使了一个个缓存淘汰算法的诞生和应用。
基本的缓存淘汰算法
OPT
OPT是optimal的简写,译为 最优 。OPT算法顾名思义,它是最优的算法,它淘汰的是那些以后永远不再使用、或是在最长的时间内不再使用的数据。那既然有了最优化的算法,还要别的算法干什么呢?这是因为OPT算法不可能实现,除非你事先知道数据的全部访问顺序。那一个不可能实现的算法有什么用呢?其实我们学习OPT算法是为了衡量其他算法的缓存命中率,因为任何算法的缓存命中率都不可能超过OPT算法,它代表着在给定的数据访问顺序和缓存空间大小条件下的最高缓存命中率。
FIFO、FILO、RR
这是三种见名知意的算法。FIFO是First In First Out,FILO是First In Last Out,分别使用队列和栈实现即可。RR是 Random Replacement,随机替换算法,即随机选择一个数据淘汰
LRU与LFU
LRU和LFU是最常见和最重要的两种算法,但它们也有缺陷,不能适用于任何场景。正如各个语言的sort算法都不会直接使用快排一样,大多数时候我们使用的是基于LRU或LFU改进的算法。不过在介绍这些改进算法之前,我们需要先介绍LRU和LFU。
LRU
LRU的全称是Least Recently Used,最近最少使用算法。它选择最近最少使用的数据进行淘汰,通常认为LRU是相当优秀的缓存淘汰算法。同时,也是在面试时各个算法中最容易被要求实现的一个。
要实现LRU算法,只需要使用哈希表+双向链表即可。在哈希表中存储双向链表的结点,结点中存储需要的数据,每次取用缓存中的数据时,将对应的值结点从链表中转移到链表头部;插入数据时存入哈希表并插到链表头部即可。当需要淘汰数据时,直接淘汰链表末端的数据并从哈希表中删去即可。由于时间不太充裕,笔者不提供代码实现,有需要可以直接参考LeetCode题解https://leetcode-cn.com/problems/lru-cache/solution/
另外,如果你使用的是Java语言,Java标准库已经原生携带了LinkedHashMap的数据结构并提供了LRU的功能,你只需要继承LinkedHashMap并重写removeEldestEntry方法,在外层封装成缓存ADT即可。
从算法上很容易看出来LRU非常强调时间局部性,显然绝大多数情况下它的命中率会比FIFO、FILO、RR这样的算法高很多,在这些基础的算法中,LRU被认为是最优秀的一个,但LRU也带来了一些问题。最大的问题是如果元素只被使用一次的情况,每个元素都会被使用但只被使用一次,每一个元素都会被移到链表的一端占用了最重要的位置,但之后又不再使用。最明显的例子就是遍历,如果进行一次较大规模的遍历,就会导致缓存中大量的空间被这些不再使用的数据占用,而那些真正需要频繁使用的热点数据被淘汰。
LFU
LFU的全称是 Least Frequently Used ,最不经常使用算法。它选择使用次数最少的数据淘汰,如果使用次数最少的数据有多个,从其中选择最近最少使用的数据进行淘汰。
LFU在实现上是类似LRU的。我们需要使用两个哈希表和若干个双向链表。一个哈希表维护查询数据的键以及一个双向链表结点,结点中存储数据和当前使用次数,另一个哈希表以使用次数为键存储一个双向链表,即HashMap<K,Node>与HashMap<Interger,LinkedList< Node >> , 再维护一个int记录当前缓存中的最小使用次数。
当从缓存中获取到数据时,从当前链表中删除,将使用次数+1插入到下一个链表的首部,并检查是否需要更新最小使用次数的值;插入数据时,更新最小使用次数为1,插入到1对应链表的头部;当需要进行淘汰时,选择最小使用次数对应链表的尾端数据淘汰,并检查是否需要更新最小使用次数的值即可。同样的,笔者不提供代码实现,有需要可以直接参考LeetCode题解https://leetcode-cn.com/problems/lfu-cache/solution/
LFU解决了LRU提出的问题,当进行遍历时,如果有进行淘汰的必要,淘汰的都将是那些由于遍历加入到缓存中的数据。但LFU也有缺陷,一些数据可能在过去是热点数据,但实际上已经不是热点数据了,但它们会一直占据着缓存空间导致缓存的可用空间变小。比如一个新闻,短时间内有了百万千万的浏览量,一段时间后它就不再有时效性,但有如此高的使用次数想要淘汰它是不可能的。
基于LRU与LFU的简单缓存淘汰算法
接下来我们介绍一些基于LRU和LFU做简单改动的算法。
Clock与Clock-Pro
我们在上文中提到,LRU通常被认为是很优秀的缓存淘汰算法,但除了上述的缺点之外, 它还有一个缺陷,那就是实现较为复杂。我们说过缓存在计算机领域中无处不在,在一些比较底层的地方,复杂的实现会导致较多的操作从而导致性能降低,以及在一些需要硬件直接实现缓存淘汰的地方复杂的算法会带来复杂的电路结构,因此我们需要一些简单而较为高效的淘汰算法。Clock就是这样的算法,它是LRU的一种近似,用于操作系统换页。一般来说,应用软件的缓存中并不会使用Clock及其改进的算法,但也有PostgreSQL这样使用基于Clock算法改进的算法进行缓存淘汰的软件。
Clock
在介绍Clock-Pro算法之前我们先介绍一下Clock算法。Clock算法又叫NRU,not recently used,Clock算法使用一个基于数组的一个环形的列表连接所有元素并给每一个元素设置一个访问标识位标记是否使用,用一个指针标识当前位置,并设置一个哈希表存储查询数据的键以及对应数据在数组中的索引。当访问缓存中的某一元素或写入某一元素时,将其访问位 置为1;当需要进行缓存淘汰时,检查当前元素访问位,如果为0则淘汰,如果为1则置为0,然后顺序访问下一个元素重复检查操作即可。
Clock-Pro
Clock-Pro是Clock的简单改进,在访问位的基础之上,还设置了一个修改位用于标识该元素是否被修改过。这里涉及到了操作系统的一些知识,并且前置内容比较多不便介绍,如果你还没有学习操作系统课程,感觉读不懂,可以先跳过本算法。
与Clock算法相比,Clock-Pro多了一个标记位,用于标识当前页是否被修改过,标记是否修改的目的是为了利用缓冲技术优化性能,如果一个页被修改过,需要先把页内的内容刷新到硬盘上才能淘汰本页,如果一个页没被修改过就可以直接淘汰。
算法流程与Clock基本一致,区别在于扫描选择待淘汰的页面时会依据访问位和修改位两个位判定操作
- (访问位,修改位)->操作
- 00 -> 淘汰
- 11 -> 改为 01
- 10 -> 改为 00
- 01 -> 改为00,将本页修改写回硬盘